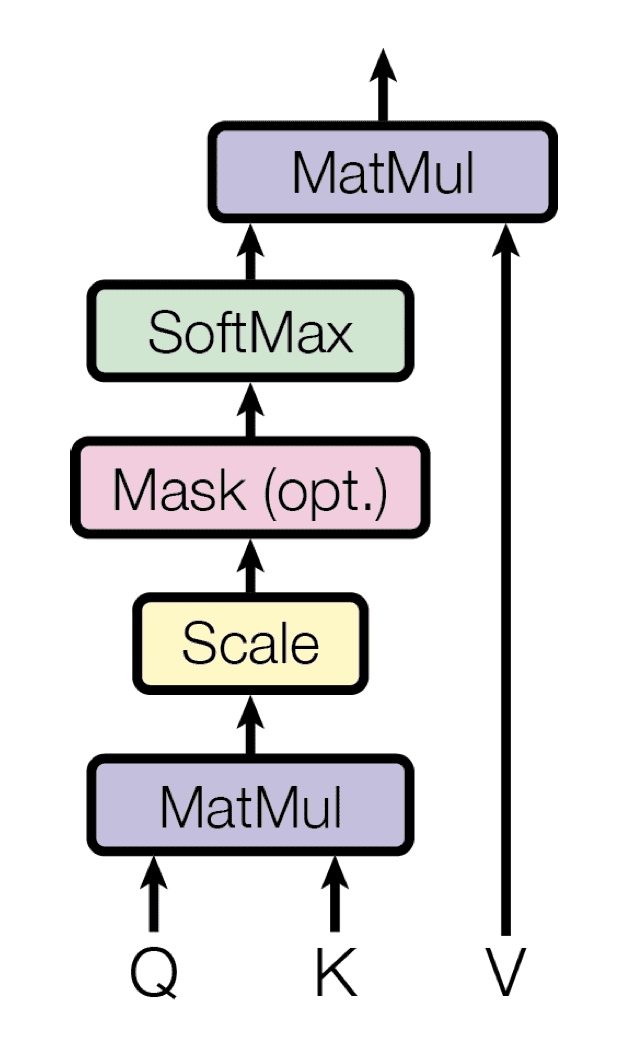
scaled dot product attention. source: Stefania Cristina
$$Attention(Q,K,V)=softmax\left(\frac{QK^{T}}{\sqrt{d_k}}\right)V$$
写一个self_attention function¶
假如input的dim是batch_size, seq_len, hidden_dim,写一个self attention function。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import torch
import math
import torch.nn.functional as F
import pytorch_lightning as pl
'''
q,k,v = (batch_size, seq_len, dim)
'''
def self_attention(q, k, v, mask=None):
d_k = k.size()[-1]
attn_logits = torch.matmul(q, k.transpose(-2,-1))
attn_logits = attn_logits / math.sqrt(d_k)
if mask is not None:
att_logits = attn_logits.masked_fill(mask == 0, -9e15)
scores = F.softmax(attn_logits, dim=-1) # 计算自注意力权重
values = torch.matmul(scores, v) # 计算自注意力分数
return values, scores
|
ChatGPT版
这里实现的self attention函数接受一个维度为(batch_size, seq_length, input_dim)的张量作为输入,其中batch_size表示批次大小,seq_length表示序列长度,input_dim表示输入特征的维度。在函数内部,我们首先使用三个线性层将输入特征映射到query、key和value空间。然后,我们通过计算query和key的点积,除以一个可学习的缩放因子,再进行softmax操作,得到注意力权重。最后,我们将注意力权重与value张量相乘,得到注意力输出,再将其映射回原始维度,并添加残差连接和层归一化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import torch
import torch.nn.functional as F
class SelfAttention(torch.nn.Module):
def __init__(self, input_dim, hidden_dim=None):
super(SelfAttention, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim if hidden_dim else input_dim // 2
self.query = torch.nn.Linear(self.input_dim, self.hidden_dim)
self.key = torch.nn.Linear(self.input_dim, self.hidden_dim)
self.value = torch.nn.Linear(self.input_dim, self.hidden_dim)
self.output = torch.nn.Linear(self.hidden_dim, self.input_dim)
def forward(self, x):
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# 计算注意力权重
attn_weights = F.softmax(torch.bmm(Q, K.transpose(1, 2)) / torch.sqrt(torch.tensor(self.hidden_dim)), dim=2)
# 计算注意力输出
attn_outputs = torch.bmm(attn_weights, V)
# 将注意力输出映射回原始维度
attn_outputs = self.output(attn_outputs)
# 添加残差连接和层归一化
attn_outputs = F.layer_norm(attn_outputs + x, [attn_outputs.size(-1)])
return attn_outputs
|